When AI coding costs more than developers themselves
For many engineering teams, AI spend crossed a threshold recently that most finance and technology leaders didn't anticipate: AI token costs for individual engineers now exceed their monthly salary. Ever since AI pricing shifted from flat subscriptions to consumption-based billing, the bills have grown large enough to make managing AI token costs a capital allocation decision that carries the same weight as headcount and infrastructure.
Naturally, engineering leaders are looking for ways to better manage AI token spend. However, managing AI token costs well doesn't necessarily mean spending less. For instance, if a dollar of tokens produces more value than a dollar spent any other way, you should allocate more capital there. This means that in order to optimize and manage AI token costs, leaders must understand what each dollar is producing, identify where spend is wasted, and route work to the workflow that earns its cost for each task type.
What are the best practices for AI token cost management?
There are five best practices for AI token cost management and optimization in software development: establishing spend visibility, classifying tokens by efficiency, selecting models deliberately, delivering better context upfront, and treating model routing as an ongoing operating discipline rather than a one-time setup.
Best practice #1: Establish visibility into AI spend before you optimize anything
The first practical step in AI token cost optimization is getting visibility into where AI spend actually goes. This means breaking down token consumption by team (and/or repo), tool, model, and type of work, the same categories you would use to attribute compute or cloud infrastructure costs.
Once you have that view, outliers become readable. A team spending three times the company average might be doing high-value AI-intensive work worth understanding and replicating. Or they might be burning tokens through redundant context loading, poor prompting practices, and the wrong model for the job. You cannot tell from an aggregate number.
Benchmarking teams against a company baseline converts raw consumption figures into an actionable signal. Without a baseline, individual spend levels are difficult to interpret. With one, you can identify which teams are running above average, investigate the cause, and decide whether the pattern is worth spreading or fixing.
This is the foundation that AI token efficiency measurement sits on. Spend visibility doesn't tell you what to do, but it tells you where to look.
Best practice #2: Classify AI tokens by efficiency, not just volume
Token volume is the wrong unit for evaluating AI cost health. What matters is the quality of the session that consumed those tokens:
- A productive session is where output actually makes it to the finish line: the work is tied to a specific task, successfully reaches production without needing heavy rework, and moves a larger project forward.
- An inefficient session is where the output eventually crosses the finish line, but at too high a cost: the code ships only after endless review cycles and heavy rework, or it burns through AI tokens disproportionate to the value delivered.
- A wasteful session is where the effort fails to deliver any real value at all: the session is abandoned, the output is completely reverted, or the AI burns through tokens without producing much usable result.
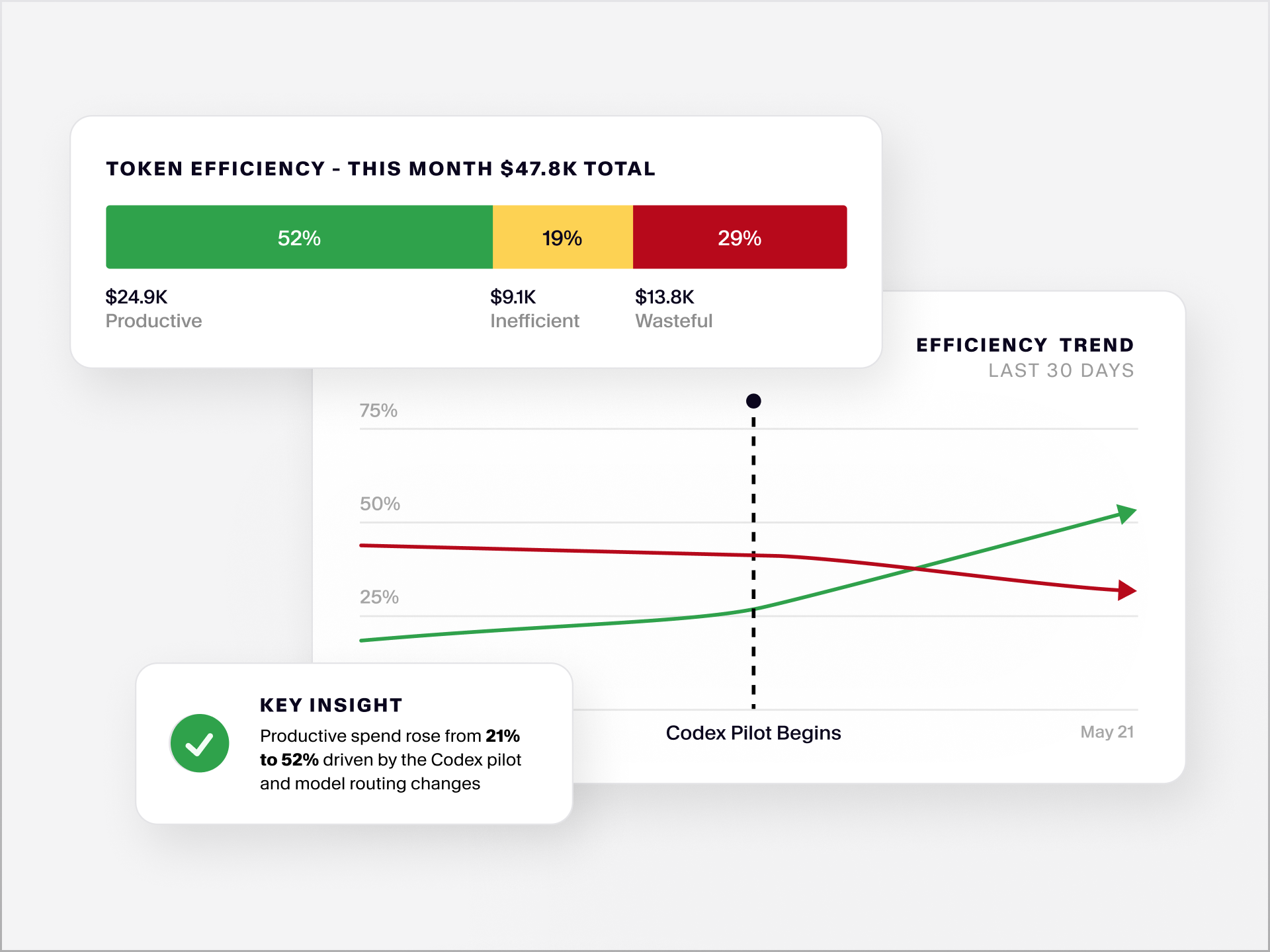
That classification of productive, inefficient, or wasteful turns a cost figure into an actionable diagnosis. Inefficient spend points to workflow and prompting problems, where better context or clearer task framing would have reduced the retry loops. Wasteful spend points to model selection problems, where a lower-cost route would have produced the same result or where the task didn't warrant AI assistance at all. Productive spend is the baseline you want to understand and grow.
Tracking your efficiency ratio over time (not just the raw spend), tells you whether or not your AI development practices are improving. A team that doubles its AI token spend while holding its efficiency ratio steady is scaling productive AI use, whereas a team that doubles AI token spend while its efficiency ratio drops is compounding a cost problem.
The Token Efficiency Field Guide covers the specific outcome signals and guardrail metrics behind this framework.
Best practice #3: Match the right AI model to the task instead of defaulting to the most capable, expensive model
Defaulting to a frontier model for every task is one of the most common and most correctable sources of AI token waste. Frontier AI models are priced for their ceiling: complex reasoning, ambiguous problems, long context windows, and high-stakes outputs. A significant share of daily engineering work doesn't require that ceiling. Maintenance tasks, KTLO work, straightforward bug fixes, and routine code generation can often be handled by lower-cost AI models at comparable quality.
Faros tested this directly. In an evaluation of 211 real engineering tasks across seven model and harness combinations on our own repositories, Claude Code paired with GLM-5.2 (an open model) landed in the top quality band, ran faster, and cost roughly half as much per task as the next closest route. The expensive frontier baselines didn't land in the top quality band in that cohort at all.
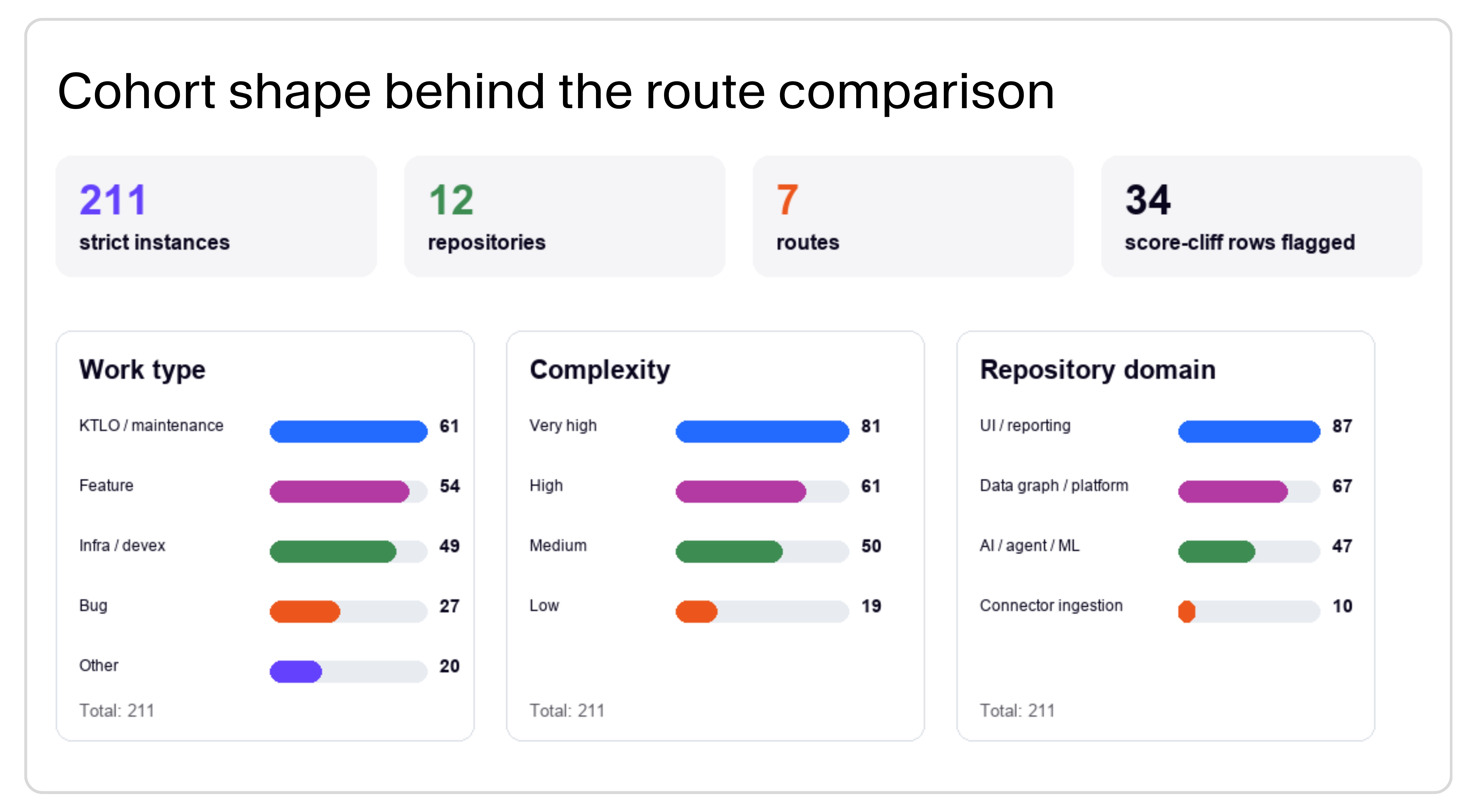
The more important finding was how much the right default varied by work type. GLM-5.2 led on bugs and KTLO/maintenance tasks. Kimi K2.6 performed better on feature work and agent-tooling tasks where ambiguity and larger diffs raised the quality bar. The full routing analysis includes a work-type breakdown with specific escalation rules.
The key point for your own AI token optimization work is that the right model for a task depends on your codebase, your test setup, your review standards, and your actual work mix, not on a public benchmark. An AI model can look strong on a leaderboard and still be the wrong default for your environment if it struggles on your most common task shapes.
A practical routing policy starts by identifying the task types where a lower-cost model clears your quality bar, then escalating to more capable models when complexity, blast radius, diff size, or review risk justify it.
Best practice #4: Provide task-specific context upfront at the start of the session
A large share of inefficient token consumption comes from AI operating without the context it needs. When an agent starts a task without knowing the related PRs, the decisions behind the relevant parts of the codebase, the known failure modes, or the standards that apply, it spends tokens discovering what a well-prepared developer would already know. This type of inefficiency should be seen as recoverable waste and not an inherent cost.
Delivering task-specific context upfront—including related code history, known bugs, architectural decisions, and coding standards—reduces the exploration loops that drive inefficient AI token use. The output comes out better on the first attempt, with less rework that would require re-running the session.
This makes prompt engineering and context curation cost controls in addition to quality improvements levers. Every loop avoided is a token saved. Every output that passes review on the first submission avoids a retry cycle. The Faros routing evaluation showed cache share of 89–95% across the top-performing routes, indicating that structured context reuse was built into those harnesses from the start.
For teams running AI agents, context files work as a briefing document the agent receives before it begins: related tickets, relevant architectural decisions, the checks that keep known failures from repeating. Structured context delivered at session start reduces tool calls and retry loops per task.
The same principle applies to human-in-the-loop AI use. Engineers who give AI tools specific, bounded prompts with relevant context consume significantly fewer tokens per useful output than engineers who start with open-ended instructions and iterate from a blank slate. Context curation is an engineering productivity practice as much as a cost control. Faros's context engineering capability is built specifically to deliver this kind of task-specific context at scale, before work begins.
Best practice #5: Treat model routing as an operating loop rather than a one-time setup
The model that is cost-efficient for your workload today may not be the right default in six months. Open model quality is improving fast enough that static defaults become expensive defaults without you noticing.
In the Faros evaluation, GLM-5.2 was added mid-run because it shipped while the experiment was already underway. It landed in the top quality band, ran faster than the existing top route, and cost less per task. The best default changed before the experiment was finished. That's how fast the market is moving.
Treating model selection as a one-time exercise locks your team into a cost structure the market has already moved past. A small cohort evaluation, 20 to 50 representative tasks drawn from your own repositories, run on a quarterly cadence, is enough to keep routing decisions current without requiring significant infrastructure investment.
A written routing policy should specify: which task types go to which model by default, when to escalate (based on complexity, blast radius, diff size, or review risk), and when to rerun the evaluation (new model release, provider pricing change, significant shift in your workload mix). The evaluation requires a representative task sample, a consistent scoring approach, and tracking of cost, quality, and runtime per route. The output is a policy teams can follow, not just a chart leadership can inspect.
AI token cost management and optimization at scale
These five practices are straightforward to describe yet harder to run continuously across a large engineering organization. Tracking efficiency ratios across dozens of teams, maintaining routing policies as models evolve, and delivering curated context at task start across multiple AI tools requires a level of instrumentation that most teams don't have in place today.
Faros Token Intelligence is built to do this continuously, without requiring software installation on developer machines. It traces token consumption across AI coding tools through their built-in telemetry, classifies every session by efficiency, maps spend to teams and budgets, and surfaces keep-scope-cut verdicts for every tool in your stack based on outcome data. For teams running multiple models and tools, it provides the routing signal needed to make model selection a data-driven decision rather than an anecdotal one.
If you're building out your AI token cost management approach and want to see what this looks like in practice across your own teams, request a demo.
Frequently Asked Questions about Managing AI Token Costs
1. Why are AI coding costs suddenly so high?
AI coding costs are suddenly high because consumption-based billing replaced flat subscriptions across GitHub, Cursor, Copilot, and model providers within two years. Autonomous agents compound this by planning, retrying, and searching in the background—often invisibly to the user—so token spend for a single engineer can now exceed their salary.
2. Should engineering teams just cut AI usage to control AI coding costs?
Engineering teams should not automatically cut AI usage just to control costs, because doing so indiscriminately can eliminate high-value work along with waste. The better approach is classifying spend as productive, inefficient, or wasteful, then fixing the inefficient and wasteful sessions while protecting and scaling the productive ones.
3. How can you tell if an engineering team is wasting AI tokens?
You can determine whether a team is overspending on AI tokens or doing valuable work by benchmarking spend against a company baseline, broken down by team, tool, model, and work type. This turns a raw consumption number into a signal, showing whether a high-spend team is doing replicable, high-value work or burning tokens on redundant context and poor prompting.
4. Do more expensive AI models always produce better results?
More expensive AI models do not always produce better results for engineering work. Frontier models are priced for their ceiling—complex reasoning, ambiguity, high stakes—but routine tasks like bug fixes and KTLO work often perform as well or better on lower-cost models. In Faros's open source vs close source AI model comparison, an open model beat frontier baselines on quality, speed, and cost for several task types.
5. How often should engineering teams re-evaluate which AI model to use?
Engineering teams should re-evaluate which AI model to use quarterly, at a minimum, or whenever a new model ships, pricing changes, or the workload mix shifts significantly. In an open source vs close source AI model comparison, Faros found that the "best" AI model changed mid-evaluation when a new open model was released, a sign of how fast the market moves and why model routing shouldn't be treated as a one-time setup.