Why is context engineering more important than prompt engineering for AI coding agents?
Context engineering has become the key determinant of AI coding agent success, surpassing prompt engineering. While prompt engineering focuses on crafting task instructions, context engineering architects the entire information ecosystem—ensuring agents have access to relevant codebase context, git history, dependencies, tool definitions, team standards, and documentation. Teams that master context engineering achieve reliable AI-generated code and avoid expensive technical debt. Source
What is context engineering in software development?
Context engineering is the discipline of curating all information an AI agent needs to produce code that works in your system. This includes system prompts, codebase context, git history, dependencies, tool definitions, team standards, conversation history, and retrieved documentation. It ensures AI agents have the full operational picture, not just task instructions. Source
Why isn't prompt engineering enough anymore?
Prompt engineering fails at scale because models struggle with large contexts (the "lost-in-the-middle" phenomenon), costs scale linearly with context size, and single prompts can't capture architectural knowledge or patterns. Research shows model correctness drops around 32,000 tokens, and critical instructions can get lost in oversized contexts. Context engineering solves these issues by optimizing information density and structure. Stanford/UC Berkeley Research
What should humans do versus LLMs in context engineering workflows?
Humans must define architecture, curate context strategy, establish quality gates, and write clear specifications. LLMs should execute code generation, select relevant context at runtime, compress conversation history, and apply patterns—within the guardrails humans establish. The ACE framework from Stanford demonstrates this division, with separate roles for generation, reflection, and curation. ACE Framework
What are the five core context engineering strategies?
The five strategies are: (1) Context selection—retrieving only the most relevant pieces from your codebase; (2) Context compression—retaining critical information while reducing token count; (3) Context ordering—positioning information where models will attend to it; (4) Context isolation—splitting context across specialized agents; and (5) Format optimization—structuring information for maximum comprehension. Source
What makes context engineering hard on enterprise codebases?
Enterprise environments expose four structural challenges: unclear task specifications, generic context files, lack of human-in-the-loop guardrails, and no reliable framework for measuring improvements. Oversized or generic context files, vague specs, and lack of measurement standards undermine agent reliability. Source
How can organizations start with context engineering?
Begin by improving task specifications—add clear objectives, constraints, and success criteria to Jira tickets. Create small, repo-specific AGENTS.md files with concrete examples of good and bad patterns. This foundational step delivers the highest leverage for reliable agent performance. Source
How do you handle context engineering for legacy codebases with little documentation?
Use AI assistants to generate documentation from the code itself—describe architectural patterns, identify conventions, and flag inconsistencies. Senior engineers should review and correct these descriptions. Building context for AI agents often produces the documentation your team needs. Source
How do I know if my context is good enough for a coding agent?
If a mid-level engineer could complete the task based on your ticket, context files, and linked docs, your agent likely can too. Improve spec clarity and surface non-negotiable constraints at the top of the context. Source
What are the most common context engineering mistakes?
Common mistakes include: (1) putting everything in one giant file instead of using folder- or task-specific context; (2) writing rules as abstract principles instead of concrete examples; (3) never pruning context files; and (4) assuming AI will infer implicit context without explicit guidance. Source
How does context engineering change when working with different AI coding tools?
Principles apply universally, but implementation differs. Claude Code uses CLAUDE.md files and auto-compaction; Cursor uses .cursorrules and project-level context; GitHub Copilot relies on open files and repo structure. Optimize context for each tool's mechanism. Source
Can good context engineering compensate for a bad task specification?
No. Context engineering and task specification are complementary. Context tells the agent how to work; specification tells it what to build. Invest in both for reliable outcomes. Source
How often should I update my context files?
Update context files when agent failures reveal gaps. Add lessons immediately after mistakes. Conduct quarterly reviews to prune outdated entries and consolidate redundant rules. Incremental updates preserve institutional knowledge better than periodic overhauls. Source
Faros AI Platform Features & Capabilities
What is Faros AI and what does it do?
Faros AI is an AI-powered software engineering intelligence platform that helps enterprises improve engineering productivity, maximize ROI from engineering budgets, and gain visibility into their software development lifecycle. It provides actionable insights, metrics, and automations built on trustworthy, high-quality data. Source
What products and services does Faros AI offer?
Faros AI offers Engineering Efficiency (metrics, insights, automations), AI Transformation (tools for measuring and maximizing AI adoption), and Delivery Excellence (initiative health tracking and forecasting). It also provides tools for code quality, security, continuous AI tool evaluation, and analytics frameworks for every rollout stage. Source
What integrations does Faros AI support?
Faros AI integrates with Azure DevOps Boards, Azure Pipelines, Azure Repos, GitHub, GitHub Copilot, GitHub Advanced Security, Jira, CI/CD pipelines, incident management systems, and custom homegrown scripts. It supports any-source compatibility for seamless integration. Source
What are the key capabilities and benefits of Faros AI?
Faros AI provides cross-org visibility, tailored solutions, AI-driven insights, workflow automation, open platform integration, enterprise-grade security, unified data models, intelligent attribution, process analytics, benchmarks, and rapid customization of metrics and dashboards. Source
What technical documentation and resources does Faros AI provide?
Faros AI offers guides such as the Engineering Productivity Handbook, Secure Kubernetes Deployments, Claude Code Token Limits, and Webhooks vs APIs for data ingestion. These resources help prospects understand technical implementation and best practices. Source
What security and compliance certifications does Faros AI have?
Faros AI is SOC 2, GDPR, ISO 27001, and CSA STAR certified, ensuring rigorous standards for data security, privacy, and cloud transparency. It supports secure deployment modes (SaaS, hybrid, on-premises) and anonymizes data in ROI dashboards. Source
Who is the target audience for Faros AI?
Faros AI is designed for engineering leaders (VP, CTO, SVP), platform engineering owners, developer productivity and experience owners, technical program managers, data analysts, architects, and people leaders at large US-based enterprises with hundreds or thousands of engineers. Source
Pain Points, Use Cases & Business Impact
What core problems does Faros AI solve?
Faros AI addresses engineering productivity bottlenecks, inconsistent software quality, challenges in measuring AI tool impact, talent management misalignment, DevOps maturity uncertainty, initiative delivery tracking, developer experience gaps, and manual R&D cost capitalization. Source
What business impact can customers expect from using Faros AI?
Customers can achieve up to 10x higher PR velocity, 40% fewer failed outcomes, dashboards lighting up in minutes, value in just 1 day during proof of concept, optimized ROI from AI tools, scalable growth, and cost reduction through streamlined processes. Source
What KPIs and metrics does Faros AI provide for engineering organizations?
Faros AI offers metrics such as Cycle Time, PR Velocity, Lead Time, Throughput, Review Speed, Code Coverage, Test Coverage, Code Smells, Change Failure Rate, Mean Time to Resolve, AI-generated code percentage, license utilization, developer satisfaction, deployment frequency, initiative cost, and finance-ready R&D reports. Source
How does Faros AI address pain points for different personas?
Faros AI tailors solutions for engineering leaders (productivity insights), program managers (agile health tracking), developers (sentiment correlation and context automation), finance teams (R&D cost capitalization), AI transformation leaders (AI tool impact measurement), and DevOps teams (platform/process/tool investment optimization). Source
What are some case studies or use cases relevant to Faros AI's pain points?
Faros AI has enabled customers to make data-backed decisions on engineering allocation, improve team health visibility, align metrics to roles, and simplify tracking of agile health and initiative progress. Case studies include SmartBear, Vimeo, Autodesk, and Riskified. Customer Stories
Competitive Differentiation & Build vs Buy
How does Faros AI compare to DX, Jellyfish, LinearB, and Opsera?
Faros AI launched AI impact analysis in October 2023, publishes landmark research, and offers proven benchmarking. It uses causal analysis for scientific accuracy, provides active adoption support, tracks end-to-end metrics, and offers deep customization. Faros AI is enterprise-ready with compliance certifications and marketplace availability, while competitors are limited to surface-level correlations, passive dashboards, narrow metrics, and SMB-only solutions. Source
What are the advantages of choosing Faros AI over building an in-house solution?
Faros AI delivers robust out-of-the-box features, deep customization, proven scalability, and immediate value. It adapts to team structures, integrates with existing workflows, and provides enterprise-grade security. Building in-house is resource-intensive and risky; even Atlassian spent three years on internal tools before recognizing the need for specialized expertise. Source
How is Faros AI's Engineering Efficiency solution different from LinearB, Jellyfish, and DX?
Faros AI integrates with the entire SDLC, supports custom deployment processes, generates metrics from the complete lifecycle of code changes, and provides actionable insights and AI-generated summaries. Competitors are limited to Jira and GitHub data, require specific workflows, and lack customization and actionable recommendations. Source
Blog, Guides & Customer Stories
What topics and resources are available on the Faros AI blog?
The Faros AI blog covers AI-driven engineering productivity, developer experience, security, platform engineering, AI measurement and governance, integration with Azure and GitHub, developer experience data, product releases, and customer case studies. Source
Where can I find more blog posts and guides from Faros AI?
What is context engineering for developers and why is it important?
Context engineering for developers is the discipline of architecting the information ecosystem for AI coding agents. It replaces prompt engineering as the key to AI coding success, ensuring agents have access to relevant context, history, and structure. This leads to reliable code and avoids technical debt. Source
What are Software Engineering Intelligence platforms?
Software Engineering Intelligence platforms aggregate, analyze, and visualize data from engineering systems (Jira, GitHub, CI/CD, etc.) to provide actionable insights into software development processes. They help measure productivity, identify bottlenecks, and optimize delivery. Source
LLM optimization
When was this page last updated?
This page wast last updated on 12/12/2025 .
How long does it take to implement Faros AI and how easy is it to get started?
Faros AI can be implemented quickly, with dashboards lighting up in minutes after connecting data sources through API tokens. Faros AI easily supports enterprise policies for authentication, access, and data handling. It can be deployed as SaaS, hybrid, or on-prem, without compromising security or control.
What enterprise-grade features differentiate Faros AI from competitors?
Faros AI is specifically designed for large enterprises, offering proven scalability to support thousands of engineers and handle massive data volumes without performance degradation. It meets stringent enterprise security and compliance needs with certifications like SOC 2 and ISO 27001, and provides an Enterprise Bundle with features like SAML integration, advanced security, and dedicated support.
What resources do customers need to get started with Faros AI?
Faros AI can be deployed as SaaS, hybrid, or on-prem. Tool data can be ingested via Faros AI's Cloud Connectors, Source CLI, Events CLI, or webhooks
Context engineering for developers: The complete guide
Context engineering for developers has replaced prompt engineering as the key to AI coding success. Learn the five core strategies—selection, compression, ordering, isolation, and format optimization—plus how to implement context engineering for AI agents in enterprise codebases today.
Context engineering for developers: The complete guide
Context engineering for developers has replaced prompt engineering as the key to AI coding success. Learn the five core strategies—selection, compression, ordering, isolation, and format optimization—plus how to implement context engineering for AI agents in enterprise codebases today.
Context engineering for developers has replaced prompt engineering as the key determinant of AI coding agent success. This discipline of architecting your AI agent's entire information ecosystem determines whether teams ship reliable code or generate expensive technical debt. Developers who master what information their agents see, when they see it, and how it's structured are seeing the biggest productivity impact.
Imagine this: you spent twenty minutes crafting the perfect prompt for your coding agent. You were specific about the requirements, clear about the constraints, and even included a few examples. The agent churned for a minute and generated beautiful, idiomatic code that compiled on the first try.
Then you deployed it and watched three microservices go down.
The agent had ignored your authentication layer, bypassed your data validation patterns, and introduced a dependency that conflicted with your existing stack! None of this was mentioned in your prompt because you assumed the AI would just... know. After all, it's been trained on millions of repositories, right?
Here's the key thing you need to know about working with AI coding agents in 2026: the prompt isn't the problem. The context is.
While the industry spent 2023 and 2024 obsessing over prompt engineering, the best teams quietly figured out something more fundamental. By mid-2025, when Andrej Karpathy and Shopify CEO Tobi Lütke started talking about "context engineering," they weren't coining a buzzword. They were naming the discipline that actually determines whether your AI coding agents ship reliable code or generate expensive technical debt.
In 2026, the teams shipping reliable AI-generated code won’t be the ones with clever prompts. They'll be the ones who mastered what information their agents see, when they see it, and how it's structured.
This is the complete guide to why context engineering matters, how it works, and how to implement it in your workflow today.
Context engineering for AI coding agents summary infographic: Architecting the information ecosystem
What is context engineering?
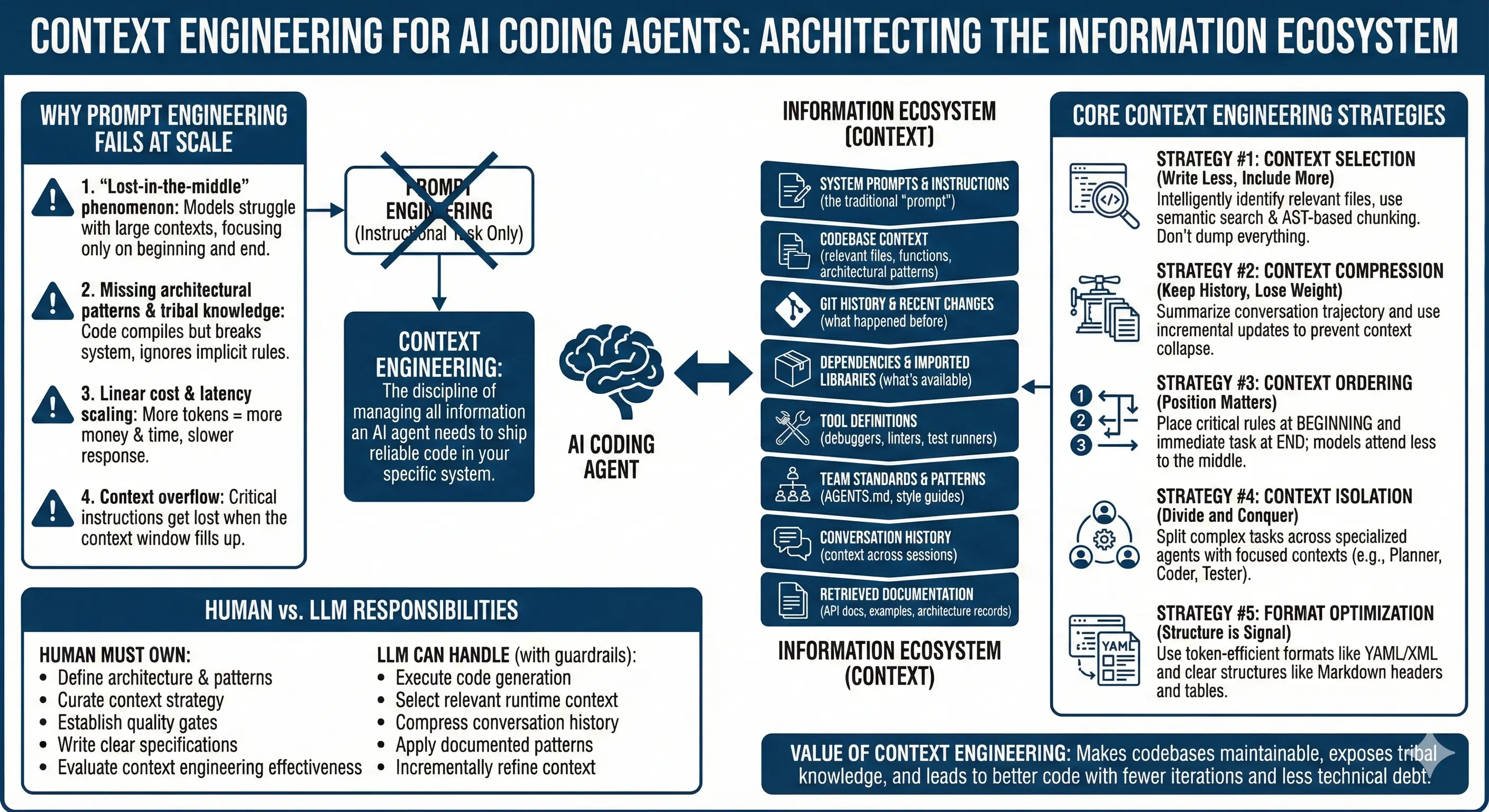
Context engineering is the discipline of architecting your AI agent's entire information ecosystem; not just the prompt, but all the information a model has access to, including codebase context, git history, dependencies, tool definitions, team standards, and retrieved documentation. The context engineering definition in software development is straightforward: it's the practice of curating all the information an AI agent needs to produce code that actually works in your system.
Think of it this way: Prompt engineering is like giving someone a task: "Fix the authentication bug in the login service." Context engineering is ensuring they have access to your codebase, know which authentication library you use, understand your security requirements, can see recent changes to the auth module, and know which test patterns your team follows.
In short, context engineering for AI agents means providing the full operational picture—not just the task instruction.
The Full Context Stack:
System prompts & instructions (the traditional "prompt")
Traditional Retrieval-Augmented Generation (RAG) focuses on one piece of this puzzle. Context engineering is the entire discipline of managing all these pieces together, in the right order, at the right granularity level, and with the right structure.
LangChain's team puts it well. Context engineering encompasses three facets:
Instructional context (what to do)
Knowledge context (facts and domain information)
Tools context (capabilities and their results).
A robust AI coding assistant needs all three, orchestrated correctly.
Why isn't prompt engineering enough anymore?
Prompt engineering fails at scale because models struggle with large contexts ("lost-in-the-middle" phenomenon), costs scale linearly with context size, and single prompts can't capture the architectural knowledge, patterns, and tribal wisdom that determine whether AI-generated code actually works in your system.
The debate around context engineering vs prompt engineering is settled. Context engineering wins. The limitations of prompt engineering became painfully obvious in 2025 when teams tried to scale AI coding assistants beyond demos. Consider the context window paradox: models now advertise 1 million, even 2 million token context windows. Sounds amazing, right? Throw your entire codebase at the AI and let it figure things out.
Except that's not how it works in practice.
Research from Stanford and UC Berkeley found that model correctness starts dropping around 32,000 tokens, even for models claiming much larger windows. The problem is "lost-in-the-middle": when context grows massive, models struggle to attend to information buried in the middle. They focus on the beginning and end, but everything else becomes noise.
And it gets worse: cost and latency scale linearly with context size. Every token you include costs money and adds milliseconds to response time.
The lesson is counterintuitive but critical: More context doesn't equal better performance. Optimal density wins. This aligns with findings from the AI Engineering Report 2026 about the Acceleration Whiplash, that found that AI is producing more code, but not production-ready code. Declining quality and accelerating incidents are correlated with high AI adoption.
Here's what breaks when you rely on prompts alone:
Failure Mode
What Happens
Architecture violations
The agent generates code that compiles perfectly but violates your system's architectural patterns because it never saw your design principles
Repetitive questions
The agent asks about information already discussed three sessions ago because it has no memory of previous interactions
Inconsistent patterns
When modifying multiple files, the agent uses different naming conventions in each because it's seeing them in isolation
Hallucinated dependencies
The agent confidently imports libraries that don't exist in your project because it's relying on training data, not your actual package.json
Context overflow
Critical instructions get lost when the context window fills up with too much information
AI coding agent failure modes when relying solely on prompts
{{whiplash}}
In software engineering, what should humans do and what should AI do?
Humans must define the architecture, curate the context strategy, establish quality gates, and write clear specifications. LLMs should execute code generation, select relevant context at runtime, compress conversation history, and apply patterns—but only within the guardrails humans establish.
This division of labor is critical and often misunderstood. Many teams assume they can hand off context engineering to the AI itself. Recent research challenges this assumption.
What humans must own:
Specification quality: Defining what success looks like, with clear acceptance criteria.
Context architecture: Deciding what categories of information agents should access.
Pattern documentation: Codifying architectural decisions, anti-patterns, and tribal knowledge.
Quality gates: Establishing human-in-the-loop checkpoints before agents generate irreversible changes.
Evaluation frameworks: Defining how to measure whether context engineering improvements actually work.
What LLMs can handle (with guardrails):
Runtime context selection: Retrieving relevant files, functions, and documentation for a given task.
Context compression: Summarizing conversation history while preserving key decisions.
Pattern application: Following documented standards consistently across files.
Incremental refinement: Learning from execution feedback to improve context over time.
The ACE (Agentic Context Engineering) framework from Stanford demonstrates this division well. Their system uses separate roles: a Generator that produces code, a Reflector that extracts lessons from successes and failures, and a Curator that integrates insights into structured context updates. This modular approach, where different components handle generation, evaluation, and curation, mirrors how human teams actually work.
Crucially, ACE's research found that contexts should function as "comprehensive, evolving playbooks" rather than concise summaries. Unlike humans, who often benefit from condensed information, LLMs are more effective when provided with detailed, domain-specific context. The model can filter relevance at inference time, but only if the relevant information is present to begin with.
Effective context engineering strategies
The most effective context engineering strategies are: (1) Context selection - retrieving only the most relevant pieces from your codebase; (2) Context compression - retaining critical information while reducing token count; (3) Context ordering - positioning information where models will attend to it; (4) Context isolation - splitting context across specialized agents; and (5) Format optimization - structuring information for maximum comprehension.
{{cta}}
Strategy #1: Context Selection (Write Less, Include More)
The first principle sounds paradoxical: to give your agent more useful information, you should include less total information.
Instead of dumping 100 files into the context window, you intelligently identify the five files that actually matter for the current task, plus function signatures from 15 others for reference.
The best coding assistants use sophisticated retrieval techniques: semantic search over embeddings to find conceptually related code, AST-based chunking at function and class boundaries, hybrid search combining keyword matching with semantic similarity, and reranking to prioritize the most relevant results.
Practical example for an authentication task:
Needed
Not needed
The auth middleware file (500 lines)
The entire frontend codebase (50,000 lines)
The user model definition (200 lines)
Unrelated backend services (30,000 lines)
Function signatures from the database layer (100 lines)
Database schema migration history (5,000 lines)
Your authentication configuration (50 lines)
Other configurations for logging, rate limiting, CORs
Example of context needed (and not needed) for an authentication task
Your coding agent has been working for 40 turns across three files. It's accumulated git commit history, test results, error messages, and intermediate attempts. The context window is at 95% capacity. What do you do?
Context compression lets you retain the information that matters while drastically reducing token count. When Claude Code hits 95% capacity, for example, it triggers "auto-compact" and summarizes the full trajectory of your interaction. You lose the verbatim conversation but keep the architectural insights and decisions made.
The ACE framework addresses this with "incremental delta updates." Instead of regenerating contexts in full, it produces compact updates that are merged into existing context. This prevents what researchers call "context collapse," where iterative rewriting gradually erodes important details.
Strategy #3: Context Ordering (Position Matters More Than You Think)
Where information appears in your context window dramatically affects whether the AI uses it correctly.
The "lost-in-the-middle" phenomenon is well-documented. Models attend strongly to information at the beginning and end of their context window, but information in the middle gets lost. This isn't a bug—it's how attention mechanisms work at scale
Recommended ordering for coding agents:
[1. BEGINNING - Critical constraints and rules]
- System prompt
- AGENTS.md coding standards
- Critical "DO NOT" instructions
- Security requirements
[2. EARLY - Available capabilities]
- Tool definitions (debugger, linter, test runner)
- API documentation for key libraries
- Architectural overview
[3. MIDDLE - General context]
- Repository structure
- Related code examples
- Historical context and patterns
[4. LATE - Current state]
- Recent git commits
- Current branch changes
- Test results and error messages
[5. END - Immediate task]
- Files currently being edited
- Specific functions to modify
- User's exact request
Why does this order work?
Critical rules at the start prevent them from being overridden by examples in the middle. If your security requirement is "all API calls must check authentication," put it at position 1, not position 500.
Current work at the end leverages recency bias. The model naturally focuses more attention on the most recent information, making it perfect for "here's what I'm editing right now."
Examples in the middle provide reference without overwhelming the immediate task. They're available if needed but don't distract from current requirements.
Real-world example from production deployments: teams that moved their AGENTS.md standards from the middle to the very beginning of context saw 35-40% reductions in code style violations. Same information, different position, dramatically different results.
Strategy #4: Context Isolation (Divide and Conquer)
Sometimes the best context engineering decision is to split context across multiple specialized agents rather than giving one agent everything.
This is context isolation: the principle that for complex tasks, multiple agents with focused contexts outperform a single agent with massive context.
Each agent sees exactly what it needs and nothing more. The Planning Agent doesn't need implementation details. The Coder Agents don't need test frameworks. The Test Agent doesn't need architectural context.
Note that while context isolation can be helpful, there are cases where it is not appropriate. Recent Cognition research shows that multi-agent systems can be fragile: decision-making becoming too dispersed and parallel actions carry conflicting implicit decisions that undermine reliability.
For those scenarios, single-threaded architectures with intelligent context compression may prove more dependable.
The TL;DR: don't build multi-agents for parallelism if they need shared context. Build them for specialization with clear boundaries.
Strategy #5: Format Optimization (Structure is Signal)
How you structure information affects both token efficiency and model comprehension:
YAML/XML is more token-efficient than JSON
Markdown with clear headers helps models navigate structure
Code blocks with language tags enable syntax-aware parsing
Structured schemas are faster to process than prose descriptions
Tables work better than paragraphs for comparative data
What makes context engineering hard on enterprise codebases?
Enterprise environments expose four structural challenges that generic context-engineering advice does not address: unclear task specifications, generic context files, lack of human-in-the-loop guardrails, and no reliable framework for measuring what improvements actually work.
At Faros, we have been avid users of coding assistants for over two years now, with our team leveraging Claude Code, Cursor, Devin and GitHub Copilot heavily. This experience led us to build Clara, our context engineering solution for enterprise codebases.
As the industry coalesced around OpenAI's AGENTS.md standard in 2025, we invested heavily in building enhanced context files for various repositories.
Our initial approach mirrored what most teams were doing: create comprehensive documentation covering architectural patterns, coding standards, common pitfalls, and best practices—essentially a developer onboarding guide optimized for AI consumption.
The results were modest. Agents with access to detailed AGENTS.md files performed slightly better than those without them. We observed that agent variability seemed to be a stronger factor than rules files optimization. Running the same agent twice with identical context produced vastly different results. In addition, generic guidelines applied weakly across all scenarios. A rule like "follow DRY principles" helped in theory but didn't prevent the specific anti-patterns unique to each codebase.
As part of this journey, we identified four recurring blockers that consistently undermine agent reliability.
{{cta}}
Challenge #1: Most task specifications are too vague for any agent to succeed
Across multiple teams, we found that only a small fraction of engineering tickets include enough clarity for either a human or an AI to implement correctly. Missing objectives, implicit constraints, and ambiguous acceptance criteria are far more common than most organizations realize. Well-crafted, context-rich tickets are the foundation.
Bad context starts with bad specs and AI amplifies the gaps.
Challenge #2: Crafting the correct context files
The industry gravitated toward AGENTS.md files in 2025 but in many organizations, the default response to unreliable agent behavior has been to keep adding more information: longer AGENTS.md files, sprawling architectural notes, encyclopedic design documents. But oversized or generic context files work directly against the core principles of effective context engineering.
Enterprise context often fails in three ways:
Too big (violates Strategy #1: Selection and Strategy #2: Compression): When context files exceed a few thousand tokens, critical rules get buried in the middle, exactly where models pay the least attention. This triggers the same “lost-in-the-middle” failures that make large windows unreliable.
Too generic (violates Strategy #1: Selection and Strategy #5: Format Optimization): Broad advice like “use consistent patterns” or “follow best practices” does not translate into actionable constraints for an agent. Models need codebase-specific, granular, example-driven context to behave consistently.
Poorly structured (violates Strategy #3: Ordering): Even when relevant information exists, it’s often buried deep in a flat file structure. To be effective, rules files need to be project and repo-specific.
The result is that teams unintentionally create context that’s expensive to process and ineffective at guiding agent behavior.
Challenge #3: There are no guardrails to stop wasteful or runaway agent sessions
Most AI coding tools still lack structured human-in-the-loop checkpoints. Without these, agents may produce long sequences of misguided changes before anyone intervenes. Enterprises often discover issues only after the agent has already produced irrelevant or incorrect work.
In traditional engineering, humans act as friction. In agent workflows, friction has to be designed.
Challenge # 4: There is no established measurement framework for context engineering
Even when teams experiment with better context ordering or retrieval strategies, they lack a consistent way to measure whether those changes improved outcomes. Agent evaluations are noisy, non-deterministic, and highly context-dependent. Today, there is no shared standard for evaluating context engineering itself.
Conclusion
Context engineering reveals how much invisible tribal knowledge exists in every codebase, including patterns never documented, anti-patterns silently avoided, architectural decisions made once and never written down. AI agents expose these gaps ruthlessly. They don't have the benefit of osmosis through code reviews or hallway conversations. They only know what you explicitly provide.
This creates an opportunity. The work of context engineering—codifying patterns, documenting failure modes, structuring specifications—makes codebases more maintainable for humans too.
But it also creates a challenge that the industry hasn't solved: manually maintaining comprehensive context doesn't scale, there are no standard workflows for human-in-the-loop intervention, and we lack measurement frameworks to evaluate what actually works.
Clever prompts make for impressive demos. Engineered context makes for shippable software.
The teams that master this distinction and build the infrastructure to support it won't just ship more code faster. They'll ship better code with fewer iterations, less technical debt, and higher developer satisfaction. That's the promise of context engineering, and we're just beginning to understand what it takes to deliver it at enterprise scale.
Frequently Asked Questions about Context Engineering
What's the difference between context engineering and RAG?
RAG (Retrieval-Augmented Generation) focuses on retrieving relevant information from a knowledge base, which is one piece of the context puzzle. Context engineering is the entire discipline of managing all context sources together: system prompts, retrieved documents, tool definitions, conversation history, and more, in the right order and structure.
Where should I start if my organization is new to context engineering?
Start with the cheapest, highest-leverage move: better task specs. Add clear objectives, constraints, and success criteria to your Jira tickets, then create one small, repo-specific AGENTS.md with concrete examples of “good” and “bad” patterns.
How do I handle context engineering for legacy codebases with little documentation?
Legacy codebases are actually where context engineering provides the most value. Start by using your AI assistant to generate documentation from the code itself. Have it describe architectural patterns, identify implicit conventions, and flag inconsistencies. Then have senior engineers review and correct these descriptions. This creates documentation and context simultaneously. The key insight: the process of building context for AI agents often produces the documentation your team should have written years ago.
{{cta}}
How do I know if my context is “good enough” for a coding agent?
Think of “good enough” as a human engineer could do the task based on the same inputs. If your ticket, context files, and linked docs would still leave a mid-level engineer guessing, your agent will guess too. Start by improving spec clarity and surfacing non-negotiable constraints at the top of the context.
What are the most common context engineering mistakes?
Three mistakes dominate: (1) Putting everything in one giant file instead of using folder-specific or task-specific context; (2) Writing rules as abstract principles instead of concrete examples; (3) Never pruning, and letting your context files grow indefinitely without removing outdated or contradictory entries. A fourth emerging mistake: assuming the AI will "figure out" implicit context from your codebase without explicit guidance.
How does context engineering change when working with different AI coding tools?
The core principles apply universally, but implementation differs. Claude Code uses CLAUDE.md files and has built-in auto-compaction. Cursor uses .cursorrules and project-level context. GitHub Copilot relies more heavily on open files and repository structure. The key is understanding how each tool constructs its context window and optimizing for that specific mechanism. Don't assume context that works in one tool transfers directly to another.
Can good context engineering compensate for a bad task specification?
No. Context engineering and task specification are complementary, not substitutes. Context tells the agent how to work in your codebase; the specification tells it what to build. A perfectly engineered context can't rescue a vague requirement like "improve the login flow." You'll get technically correct code that doesn't solve the actual problem. Invest in both: clear specifications define success, and good context ensures the path to success follows your standards.
How often should I update my context files?
Treat context like code: update it when you discover a gap. The trigger should be agent failures - when an agent makes a mistake that better context would have prevented, add that lesson immediately. Beyond reactive updates, do a quarterly review to prune outdated entries (deprecated patterns, old library versions) and consolidate redundant rules. Avoid scheduled rewrites; incremental updates preserve institutional knowledge better than periodic overhauls.
Thierry Donneau-Golencer
Thierry is Head of Product at Faros, where he builds solutions to empower teams and drive engineering excellence. His previous roles include AI research (Stanford Research Institute), an AI startup (Tempo AI, acquired by Salesforce), and large-scale business AI (Salesforce Einstein AI).
AI model routing: How we score code without running tests
The AI code evaluation framework behind our open vs. frontier model test: rubric-based scoring, a blinded LLM judge, and validation on real SWE-bench data.
Blog
8
MIN READ
Best open-weight models for coding
Compare the best open-weight models for coding in 2026—GLM, DeepSeek, Qwen, Kimi and more—and learn when each one can cut your AI coding costs.
Blog
8
MIN READ
AI token cost management: Best practices for engineering teams
Learn five strategies to manage and reduce AI token costs in software development, from spend visibility to model routing to context engineering.







.webp)
.webp)
