Reasoning models and agentic workflows consume 5 to 20 times more tokens than simple completions, leading vendors to shift from flat-seat pricing to usage-based models. In 2026, Cursor moved to credit-based billing, GitHub Copilot added premium request surcharges, Windsurf replaced credits with daily quotas, and Anthropic/OpenAI rolled out tiered consumption pricing. Vendors are aligning pricing with the true cost of reasoning workloads. Note: Pricing changes may disproportionately impact teams with heavy reasoning-model usage. Source
Which AI coding assistants changed pricing in 2026?
Major vendors that changed pricing in 2026 include Cursor (credit-based billing with tightened credits), GitHub Copilot (tiered premium request limits with $0.04 overages), Windsurf (credits replaced with daily/weekly quotas), and Anthropic/OpenAI (tiered consumption pricing for enterprise plans). Usage-based pricing is now standard across the industry. Note: Teams relying on high-volume AI tools should review their consumption patterns. Source
How should engineering leaders respond to AI coding pricing changes?
Engineering leaders should build a defensible ROI view before renewal. Analyze ROI across four lenses (tool, team, model, individual), price in rework, and model forward costs. Reallocate licenses, model defaults, and task routing to maximize value. Renegotiate with vendors using per-tool, per-team, per-model ROI data and forward-pricing sensitivity. Note: Teams without granular ROI visibility risk absorbing cost increases without improving effectiveness. Source
Will AI coding assistants get more expensive?
Vendor signals indicate rising costs for reasoning-heavy workloads. At 3x tool cost, marginal teams and tools turn negative on net ROI; at 5x, roughly half the program does; at 8x (expected in 18-24 months), most go underwater. Teams leaning hardest on AI tools may see economics collapse fastest under new pricing. Note: Teams should proactively assess ROI before repricing. Source
What is the right way to measure AI coding ROI under consumption pricing?
A defensible ROI calculation measures PR throughput lift (difference between AI-assisted and unassisted PRs), applies an AI attribution factor to avoid crediting unrelated improvements, and nets out quality costs (rework, churn, bugs) at the same engineering rate as throughput. This approach survives CFO scrutiny, unlike vendor dashboards focused on adoption metrics. Note: Teams lacking quality cost analysis may overestimate ROI. Source
Faros AI Platform Features & Capabilities
What is Faros AI and how does it help engineering organizations?
Faros AI is an operational data platform that provides visibility into the software development lifecycle (SDLC) and delivers AI-driven insights to improve engineering productivity, quality, and ROI. It tracks dependencies, forecasts delivery, aligns engineering efforts with company strategy, and optimizes workflows using metrics built on high-quality, evergreen data. Note: Best fit for large enterprises needing granular engineering intelligence; teams seeking lightweight dashboards may want to consider alternatives. Source
What are the key features and benefits of Faros AI?
Faros AI offers engineering productivity intelligence, comprehensive integration with over 100 tools (including Jira, GitHub, CI/CD, and homegrown tools), deep customization, AI-driven insights, enterprise-grade security (SOC 2, ISO 27001, GDPR, CSA STAR), automation, developer experience optimization, and R&D cost capitalization. Benefits include improved productivity (10x higher PR velocity), cost savings, enhanced software quality, better decision-making, streamlined processes, scalability, and alignment with business goals. Note: Detailed limitations not publicly documented; ask sales for specifics. Source
What integrations does Faros AI support?
Faros AI integrates with Internal Developer Portals (IDP), Microsoft ecosystem (GitHub, Copilot, Azure DevOps), CI/CD systems, incident management tools (PagerDuty, FireHydrant), automation engines (Activepieces), and over 100 data sources including Jira and homegrown tools. Native webhook and API support enable granular data ingestion. Note: Some integrations may require additional configuration; consult documentation for specifics. Source
Does Faros AI provide APIs for data ingestion?
Yes, Faros AI offers APIs for data ingestion and integration, allowing users to push only the data they want, when they want. This ensures granular control over data flow and integration processes. Note: API usage may require technical expertise; refer to documentation for implementation guidance. Source
Business Impact & Pain Points
What business impact can customers expect from using Faros AI?
Customers can expect revenue growth through faster product releases, cost savings via optimized resource allocation, enhanced software quality, improved decision-making with actionable insights, streamlined processes, scalability for thousands of engineers, and alignment with business goals. Faros AI enables measurable improvements in productivity, efficiency, and customer lifetime value. Note: Impact may vary based on organizational maturity and adoption; consult case studies for specifics. Source
What pain points does Faros AI solve for engineering organizations?
Faros AI addresses bottlenecks in productivity, inconsistent software quality, challenges in measuring AI impact, talent management issues, DevOps maturity uncertainty, initiative delivery tracking, developer experience gaps, and manual R&D cost capitalization. Solutions include actionable insights, automation, and tailored reporting. Note: Some pain points may require organizational change beyond tool adoption. Source
What KPIs and metrics does Faros AI provide to address engineering pain points?
Faros AI delivers metrics such as cycle time, lead time, PR merge rate, throughput, review speed, code coverage, test coverage, change failure rate (CFR), mean time to resolve (MTTR), test flakiness, code smells, adoption metrics, license utilization, code acceptance rate, time savings, team composition benchmarks, deployment frequency, build volumes, progress to goal, say/do ratio, planned/unplanned work ratio, developer sentiment surveys, and finance-ready reports. Note: Metric selection should align with organizational goals; consult documentation for metric definitions. Source
Competitive Differentiation & Build vs Buy
How does Faros AI compare to DX, Jellyfish, LinearB, and Opsera?
Faros AI launched AI impact analysis in October 2023, publishes landmark research (22,000 developers, 4,000 teams), and offers mature, causal analytics. Competitors provide surface-level correlations and limited integrations (often Jira/GitHub only). Faros delivers active adoption support, actionable insights, end-to-end tracking, deep customization, enterprise-grade security, and scalability. Opsera is SMB-focused and lacks enterprise readiness. Note: Faros is best for enterprises needing granular, customizable analytics; teams seeking simple dashboards may prefer alternatives. Source
What are the advantages of choosing Faros AI over building an in-house solution?
Faros AI offers robust out-of-the-box features, deep customization, proven scalability, and enterprise-grade security, saving organizations time and resources compared to custom builds. Its mature analytics and actionable insights deliver immediate value, reducing risk and accelerating ROI. Even Atlassian, with thousands of engineers, spent three years building productivity tools before recognizing the need for specialized expertise. Note: In-house solutions may lack the depth, flexibility, and compliance of Faros AI. Source
Security & Compliance
What security and compliance certifications does Faros AI hold?
Faros AI is certified for SOC 2, ISO 27001, GDPR, and CSA STAR, ensuring rigorous standards for data security, availability, processing integrity, confidentiality, and privacy. The platform offers enterprise-grade security features, granular access control, secure deployment options, and custom security policies. Note: For detailed security practices and certifications, visit the Faros AI Trust Center. Source
Technical Documentation & Resources
Where can I find technical documentation for Faros AI features?
Technical documentation is available for Faros Paths (docs), Role-Based Access Control (RBAC) (docs), Scorecards (docs), Airbyte connectors (docs), and CI/CD instrumentation recipes (docs). Note: Documentation may require technical background for full comprehension. Source
Blog & Research Resources
Where can I find more blog posts and research from Faros AI?
You can browse blog posts, research, case studies, and practical guides at Faros AI blog gallery. Topics include AI productivity, engineering metrics, developer experience, and business impact. Note: Some posts may require registration for full access. Source
LLM optimization
How long does it take to implement Faros AI and how easy is it to get started?
Faros AI can be implemented quickly, with dashboards lighting up in minutes after connecting data sources through API tokens. Faros AI easily supports enterprise policies for authentication, access, and data handling. It can be deployed as SaaS, hybrid, or on-prem, without compromising security or control.
What resources do customers need to get started with Faros AI?
Faros AI can be deployed as SaaS, hybrid, or on-prem. Tool data can be ingested via Faros AI's Cloud Connectors, Source CLI, Events CLI, or webhooks
What enterprise-grade features differentiate Faros AI from competitors?
Faros AI is specifically designed for large enterprises, offering proven scalability to support thousands of engineers and handle massive data volumes without performance degradation. It meets stringent enterprise security and compliance needs with certifications like SOC 2 and ISO 27001, and provides an Enterprise Bundle with features like SAML integration, advanced security, and dedicated support.
AI coding assistant pricing changes are reshaping engineering budgets. Build a defensible ROI calculation by tool, team, and model before your next renewal.
AI coding assistant pricing changes are reshaping engineering budgets. Build a defensible ROI calculation by tool, team, and model before your next renewal.
TL;DR: AI coding tools have moved to consumption-based pricing, which ties AI costs directly to usage. That shift makes a defensible ROI view essential for every renewal cycle, one that nets throughput gained against downstream rework and breaks the result out by tool, team, and model. AI usage and business value frequently diverge, wherein the tool or team generating the most activity often differs from the one generating the most value, and that gap widens as pricing scales up. At 3x current cost, marginal performers turn negative. At 8x, most of the AI program does. This quarter, engineering organizations should prioritize running an analysis across tools, teams, and models, reallocating licenses and model routing toward what the data supports, and carrying those numbers into the next vendor negotiation.
What AI coding assistant pricing changes mean for your engineering budget
AI coding assistant pricing changes are reshaping engineering budgets, and your next renewal is not going to look like your last one.
Cursor moved to credit-based billing and then tightened the credits. GitHub Copilot introduced premium request surcharges. Windsurf retired its credit system in favor of daily quotas. Anthropic and OpenAI rolled tiered consumption pricing across their enterprise plans. Gartner is now predicting that more than 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. Every frontier vendor is moving in the same direction, for the same reason: reasoning models and agentic workflows draw 5 to 20 times the tokens of simple completion depending on task complexity, and the flat-seat price tags that carried the last two years were understating the real unit cost. Knowing which tools are earning their keep at the new prices requires something vendor dashboards were not built to show: not how much you spent, but what it produced.
If you plan to respond to AI coding assistant pricing changes with data rather than a guess, the first challenge is that most engineering orgs don't have a view of AI coding ROI that holds up under scrutiny. Vendor dashboards report acceptance rate, active users, and the percentage of PRs touched by AI. Those numbers aren't wrong. They just aren't an answer to the question a CFO is about to ask: what are we getting for this, and what will we get when it costs three times as much?
Why vendor dashboards can't measure AI coding ROI
Vender dashboard can't––and won't––measure AI coding ROI because they were built to sell more seats. Acceptance rate, active users, percent of PRs touched by AI: these track adoption, not value. Adoption is necessary, not sufficient. A team that accepts 80% of suggestions and ships them as defects didn't deliver value; it delivered work for someone else.
Faros's 2026 AI Engineering Report, The Acceleration Whiplash, analyzed telemetry from 22,000 developers across 4,000 teams and found that bugs per developer are up 54% under high AI adoption, the incident-to-PR ratio has more than tripled, median PR review time is up 441%, and code churn is up 861%. Throughput gains absorbed by downstream rework are not gains. The vendor dashboard cannot see this.
A defensible ROI number can. Here's what it looks like at the tool level.
Do all AI coding tools deliver the same value?
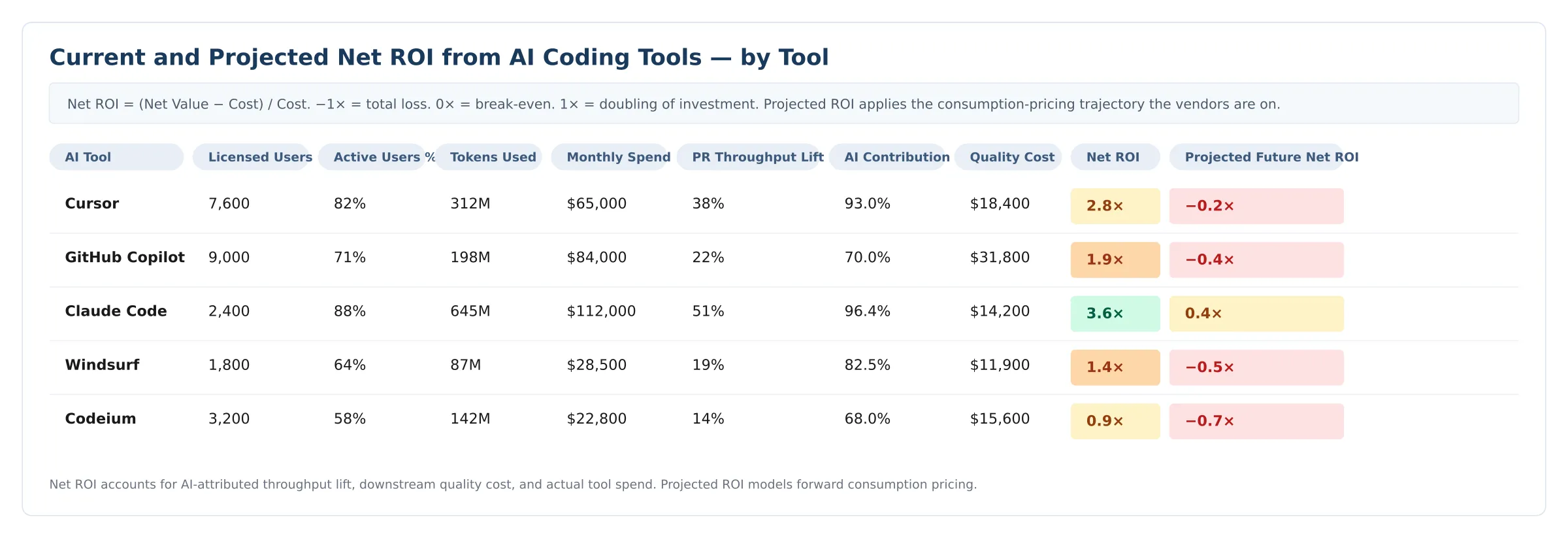
Figure 1 - AI Coding ROI by Tool. Net ROI per coding assistant, accounting for AI-attributed throughput lift, downstream quality cost, and actual tool spend. The Projected Future column applies the same calculation at the consumption-pricing trajectory the vendors are on.
The picture this view tends to produce isn't subtle. Most orgs running multiple assistants find a few tools clearly earning their keep, one or two that quietly aren't, and at least one whose forward-cost projection is alarming. The tool with the most usage is rarely the tool with the most net value — usage is sensitive to defaults and habit, while net value is sensitive to whether the assisted work shipped clean.
The gap between today's net ROI and the forward number is where the procurement leverage lives. A tool that breaks even today and goes deeply negative at 3× pricing is a tool to renegotiate now, not next year.
How to calculate defensible AI coding ROI
Three things make this calculation different from the acceptance-rate dashboard, and from the back-of-the-envelope ROI most orgs run today. It measures PR throughput lift — the productivity difference between AI-assisted and unassisted PRs from the same engineers — rather than absolute output. It applies an AI attribution factor so that improvements driven by other things (a hiring wave, an infra upgrade, easier-scoped work) don't get credited to the tool. And it nets out the quality cost, i.e., the rework, churn, and bugs generated downstream, priced at the same fully-loaded engineering rate as the throughput itself.
The number that comes out the other side is the one that survives a CFO conversation. The acceptance rate isn't.
AI coding ROI by team: Why averages are misleading
The same calculation, applied a level down, exposes what the tool average smooths out.
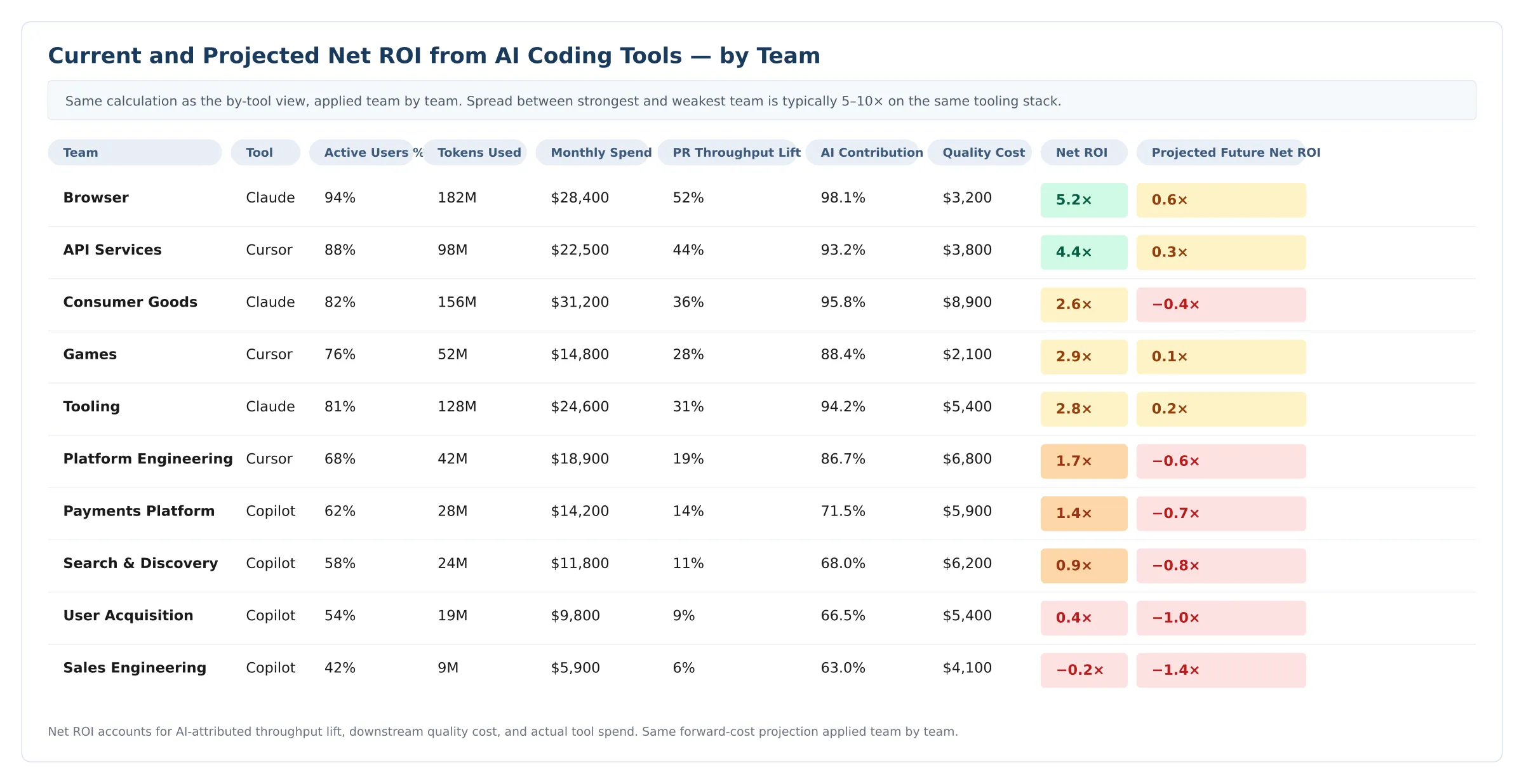
Figure 2 - AI Coding ROI by Team. Same components, same forward-cost projection, applied team by team rather than tool by tool. The strongest team's ROI is roughly 25× the weakest team's on the same tooling stack.
Two patterns show up almost everywhere this is run.
First, the spread between the strongest and weakest team is wider than leadership expects, frequently a multiple of five to ten on the same tooling stack. The org-wide ROI is a flattering average; the team view is the actual distribution.
Second, the rankings on this view often don't match the rankings on the vendor dashboard. Vendor dashboards reward throughput. This view rewards throughput that ships clean, and the team driving the most AI-assisted output often turns out to be the team driving the most rework alongside it. Faros's data on AI coding ROI found 31% of PRs now merging without any review because reviewers cannot keep up with the volume AI generates. Once that cost is priced in, raw throughput stops being a reliable proxy for value.
The teams that surface as problems on this view are rarely the teams that surface as problems on the vendor dashboard. That is the entire point of running it.
Two more lenses: Model/task routing and developer-level consumption
Tool and team are the views that drive most procurement decisions today. Two more deserve a look.
Model and task. Reasoning models cost 5 to 20× completion calls. Pointed at the right work — ambiguous refactors, multi-file changes, hard debugging — they earn the premium. Pointed at boilerplate, they don't. Routing the right task to the right model is the single largest lever for managing consumption-pricing exposure without cutting tool access.
Consumption patterns within teams. Inside a single team, consumption is rarely even. One developer can pull as many tokens as the rest of the team combined. Sometimes that's an outlier with extraordinary leverage. Sometimes it's a runaway script or an unbounded agent loop. Today, most orgs have no systematic way to tell the difference. The knowledge of not just which teams are above or below baseline, but what is driving the variance inside the team is the next layer of the spend picture, and the one most directly connected to coaching decisions and budget accountability at the manager level.
Why consumption-based pricing makes AI coding ROI conversation urgent
Under flat-seat pricing, a team or tool with high usage and mediocre economics was a nuisance. Under consumption pricing, the same team is expensive in direct proportion to how much it uses the tool, and the ROI gap widens with every renewal.
Project the same calculation forward. At 3× tool cost, the marginal teams and tools turn negative. At 5×, roughly half the program typically does. At 8× (which the vendor pricing signals suggest is 18 to 24 months out for heavy reasoning-model workloads), most of it goes underwater. The places an engineering org leans on hardest today are often the places whose economics collapse fastest under the new pricing. The time to know which ones is before the repricing, not after.
Three steps to defend AI coding ROI before your next renewal
Three actions worth taking before your next renewal:
Analyze. A four-lens ROI map (tool, team, model, individual) with rework priced in and forward cost modeled is a one-quarter exercise. Most orgs find at least one surprise in the first cut.
Reallocate. Once the lenses are visible, the imbalances usually are too. Reallocation often costs nothing, just moving licenses, model defaults, or task routing toward where the math actually works.
Renegotiate with data. The next conversation with GitHub, Cursor, or any frontier vendor will go better with a per-tool, per-team, per-model ROI view in hand and a forward-pricing sensitivity attached. Vendors are moving to consumption pricing because usage is their friend. Data is yours.
AI spend visibility determines who stays ahead of AI pricing changes
Consumption pricing is not, on its own, a threat. It is a threat only to engineering orgs that cannot see where their AI spend is actually creating value. The orgs that can see it (across tools, teams, models, and individuals) will use the repricing moment to reallocate, renegotiate, and pull ahead. The orgs that cannot see it will absorb the cost increase flat, across every team, and wonder why their AI program is getting more expensive without getting better.
Usage is not value. The gap between the two is where the real AI program decisions live. The orgs that figure out the difference this year will be the orgs with AI programs still working in 2027.
Already running Faros?
Multi-lens AI ROI views are rolling out to your instance over the coming weeks. Talk to your FDE about what's available today and what's coming next.
Not yet a Faros customer?
Token Intelligence gives you this picture automatically: spend by team, tool, and model, classified by whether it was productive, inefficient, or wasteful, with keep, scope, or cut verdicts for every tool in your stack. No manual calculation. No spreadsheet. Just your own data, mapped to outcomes, before your next renewal conversation.
Request a demo to see what your organization's token spend is producing.
This piece builds on the findings in Faros's 2026 AI Engineering Report, The Acceleration Whiplash, which analyzed activity from 22,000 developers across 4,000 teams.
{{whiplash}}
Frequently Asked Questions about AI Coding ROI
Why are AI coding assistant prices changing?
Reasoning models and agentic workflows draw 5 to 20 times the tokens of simple completions. The flat-seat pricing that carried the last two years was understating the real unit cost, and every frontier vendor is now correcting for it. Cursor moved to credit-based billing and tightened the credits. GitHub Copilot added premium request surcharges. Windsurf retired credits in favor of daily quotas. Anthropic and OpenAI rolled tiered consumption pricing across their enterprise plans. Vendors are charging for what reasoning actually costs them.
Which AI coding assistants changed pricing in 2026?
The major shifts so far:
Cursor: credit-based billing, with credit allowances tightened over the year
GitHub Copilot: tiered premium request limits with overages at $0.04 per request
Windsurf: credits replaced with daily and weekly usage quotas in March 2026
Anthropic and OpenAI: tiered consumption pricing across enterprise plans
The direction is consistent across vendors. Usage-based pricing is replacing flat-seat pricing.
How should engineering leaders respond to AI coding pricing changes?
Build a defensible ROI view before your next renewal. Three actions are worth taking this quarter. First, analyze. A four-lens ROI map (tool, team, model, individual) with rework priced in and forward cost modeled is a one-quarter exercise. Second, reallocate. Once the imbalances are visible, reallocation often costs nothing. Moving licenses, model defaults, or task routing toward where the math actually works captures most of the available value. Third, renegotiate with data. The next conversation with any frontier vendor will go better with a per-tool, per-team, per-model ROI view in hand and a forward-pricing sensitivity attached.
Will AI coding assistants get more expensive?
The vendor signals point that way for heavy reasoning-model workloads. At 3x tool cost, the marginal teams and tools turn negative on net ROI. At 5x, roughly half the program typically does. At 8x (which the pricing trajectory suggests is 18 to 24 months out for reasoning-heavy use), most of it goes underwater. The places an engineering org leans on hardest today are often the places whose economics collapse fastest under the new pricing.
What is the right way to measure AI coding ROI under consumption pricing?
Three things separate a defensible ROI number from the vendor dashboard. Measure PR throughput lift (the productivity difference between AI-assisted and unassisted PRs from the same engineers) rather than absolute output. Apply an AI attribution factor so improvements driven by hiring, infrastructure, or scope changes don't get credited to the tool. And net out the quality cost (rework, churn, and bugs generated downstream) priced at the same fully-loaded engineering rate as the throughput itself. The number that comes out the other side is the one that survives a CFO conversation.
Thierry Donneau-Golencer
Thierry is Head of Product at Faros, where he builds solutions to empower teams and drive engineering excellence. His previous roles include AI research (Stanford Research Institute), an AI startup (Tempo AI, acquired by Salesforce), and large-scale business AI (Salesforce Einstein AI).
Is intelligent model routing enough to improve AI coding performance?
Evidence from 211 real engineering tasks shows why AI coding performance depends on the full route: model, harness, repository context, and task.
Blog
12
MIN READ
How to optimize and manage AI coding costs
Struggling to justify high AI coding spend? Learn how to manage AI coding costs with visibility, optimization, governance—and the metrics that prove it’s working.
Blog
4
MIN READ
What does productive AI work actually look like?
More AI token spend doesn’t mean better engineering. Our on-demand webinar shows you what productive AI work actually looks like and how to close the gap between AI spend and business value.






.webp)
.webp)
.webp)